Sarsa Update Rule - Reinforcement learning: Temporal-Difference, SARSA, Q ... - Here, rho is updated on each iteration only if a greedy action is chosen at state s.
Dapatkan link
Facebook
X
Pinterest
Email
Aplikasi Lainnya
Sarsa Update Rule - Reinforcement learning: Temporal-Difference, SARSA, Q ... - Here, rho is updated on each iteration only if a greedy action is chosen at state s.. Here, the update equation for sarsa depends on the current state, current action, reward obtained, next state and next action. Maybe it is related to the parameter w. The estimation policy is greedy. Sarsa, does not make use of the action taken in st+1, action selection can occur after the update. Because sarsa does not take the maximum action value during the update rule, but does so instead during the computation of the greedy policy, there is a weaker decoupling of the two tables.
Sarsa is particularly appropriate when combined with function approximation (which we will discuss later) and/or when the domain is not strictly markov. ∆ wik ∝ rt + γq(s the other q(s it is possible to derive update rules that use the actual gradient. The following python code demonstrates how to implement the sarsa algorithm using the openai's gym module to load the environment. If a state s is terminal (goal state or end state) then, q(s, a) = 0 ɐ a ∈ a where a is the set of all possible actions. Because sarsa does not take the maximum action value during the update rule, but does so instead during the computation of the greedy policy, there is a weaker decoupling of the two tables.
PPT - TD(0) prediction Sarsa , On-policy learning Q ... from image1.slideserve.com Sarsa is particularly appropriate when combined with function approximation (which we will discuss later) and/or when the domain is not strictly markov. Finally, note that the sarsa update under the maximum entropy mellowmax policy could be thought of as a. Update equation of the action values in sarsa for a state s. In sarsa the next action was picked before the update. Na = env.action_space.n state = env.reset() action = eps_greedy(eps, q, state, na) score = 0 while true It learns the $q$ values of the policy that it's following. Tool useful for machine learning. For updates on the current situation regarding sars, refer to other pages on cdc's sars website.
Sarsa, does not make use of the action taken in st+1, action selection can occur after the update.
As i know that the main reason for using expected sarsa instead of sarsa is to reduce the double stochastity of sarsa. Here, the update equation for sarsa depends on the current state, current action, reward obtained, next state and next action. Because sarsa does not take the maximum action value during the update rule, but does so instead during the computation of the greedy policy, there is a weaker decoupling of the two tables. Finally, note that the sarsa update under the maximum entropy mellowmax policy could be thought of as a. It is a type of markov decision process policy. Tool useful for machine learning. An alternative softmax operator for reinforcement learning. It learns the $q$ values of the policy that it's following. Set an alternate data directory. For sarsa, its update rule is: Once again, these methods are distinguished by the. See for example baird and moore (1999). Travel information is provided on cdc's travelers' health website.
Update equation of the action values in sarsa for a state s. It is a type of markov decision process policy. Na = env.action_space.n state = env.reset() action = eps_greedy(eps, q, state, na) score = 0 while true ∆ wik ∝ rt + γq(s the other q(s it is possible to derive update rules that use the actual gradient. Introduction to reinforcement learning by sutton and barto — 6.7.
Double Sarsa and Double Expected Sarsa with Shallow and ... from html.scirp.org This update contains additional details about the reported sars cases. Maybe it is related to the parameter w. Here, the update equation for sarsa depends on the current state, current action, reward obtained, next state and next action. A sarsa agent interacts with the environment and updates the policy based on actions taken, hence this is known as an a low (infinite) initial value, also known as optimistic initial conditions,4 can encourage exploration: It is a type of markov decision process policy. However, while the agent chooses an action, the. Introduction to reinforcement learning by sutton and barto — 6.7. As i know that the main reason for using expected sarsa instead of sarsa is to reduce the double stochastity of sarsa.
However, while the agent chooses an action, the.
The estimation policy is greedy. Here, the update equation for sarsa depends on the current state, current action, reward obtained, next state and next action. Update rule def generate_sarsa_episode(env, q, eps, alpha, gamma): ∆ wik ∝ rt + γq(s the other q(s it is possible to derive update rules that use the actual gradient. It learns the $q$ values of the policy that it's following. No matter what action takes place, the update rule causes it to have higher. Maybe it is related to the parameter w. The 'update' to the value of s1 is going to be equal to the dierence between the reward (rt (s1)) at step t and the estimate (vt −1(s1)) at the previous time step t − 1. This update contains additional details about the reported sars cases. Tool useful for machine learning. Travel information is provided on cdc's travelers' health website. Of expected sarsa's update rule (5) for the case when. Because sarsa does not take the maximum action value during the update rule, but does so instead during the computation of the greedy policy, there is a weaker decoupling of the two tables.
Conatins the information of datafields (keyfigures in case of infocube and any infoobject type in case of ods). It is a type of markov decision process policy. For sarsa, its update rule is: In sarsa the next action was picked before the update. A general sarsa implementation, an a.i.
Reinforcement learning: Temporal-Difference, SARSA, Q ... from miro.medium.com The sarsa update is a parameter update rule where the target for input (st , at ) is rt +γq(s the update for wik is given by b t+1 , at+1 ) − q(s b t , at ) sti htk. The 'update' to the value of s1 is going to be equal to the dierence between the reward (rt (s1)) at step t and the estimate (vt −1(s1)) at the previous time step t − 1. It learns the $q$ values of the policy that it's following. This update contains additional details about the reported sars cases. Finally, note that the sarsa update under the maximum entropy mellowmax policy could be thought of as a. No matter what action takes place, the update rule causes it to have higher. I want to modify the sarsa algorithm so that it is suitable for average reward (undiscounted) problems, in the same way that the. Sarsa is particularly appropriate when combined with function approximation (which we will discuss later) and/or when the domain is not strictly markov.
Finally, note that the sarsa update under the maximum entropy mellowmax policy could be thought of as a.
Update rule def generate_sarsa_episode(env, q, eps, alpha, gamma): As i know that the main reason for using expected sarsa instead of sarsa is to reduce the double stochastity of sarsa. Conatins the information of datafields (keyfigures in case of infocube and any infoobject type in case of ods). Once again, these methods are distinguished by the. Updaterule info (directory of updaterules where the overview of updaterule is stored). Travel information is provided on cdc's travelers' health website. If a state s is terminal (goal state or end state) then, q(s, a) = 0 ɐ a ∈ a where a is the set of all possible actions. The sarsa update is a parameter update rule where the target for input (st , at ) is rt +γq(s the update for wik is given by b t+1 , at+1 ) − q(s b t , at ) sti htk. The 'update' to the value of s1 is going to be equal to the dierence between the reward (rt (s1)) at step t and the estimate (vt −1(s1)) at the previous time step t − 1. Maybe it is related to the parameter w. Because the update rule of expected sarsa, unlike. Moreover the variance of traditional sarsa is larger than expected sarsa but when do we need to use use traditional sarsa? No matter what action takes place, the update rule causes it to have higher.
Elsa Dress Up : Frozen Elsa Classic Toddler Dress Up / Role Play Costume ... : Get creative and combine these items into the perfect outfit. . New games are added daily! Get creative and combine these items into the perfect outfit. How to play elsa dress up for school. Handicraft dress up for elsa. Elsa and anna roller skating. You can play our elsa dress up games and have fun. Fun frozen elsa dress up games. Dress up your little princess in style you'll also get plenty of discounts when you shop for elsa dress during big sales on aliexpress. Elsa and anna roller skating. So join us for makeovers, makeup, dress up, hair styles, beauty treatments, spa, salon. Girls Quality Disney Frozen 2 Elsa Dress Elsa Dress Up ... from wishiny.com You can play elsa party dress up in your browser for free. All of these elsa dress up online are free to play. Elsa ...
How To Make Diabetic Sauce For Stir Fry? - Easy Three Ingredient Stir Fry Sauce (So easy to make stir ... : This recipe is only 272 calories for 1/2 cup sauce, which can be used to make a dish for two people. . Here we show you how to make a cheat's teriyaki sauce, an easy sweet and sour sauce, and a quick satay sauce. If you have a wok, always use it. Watch the video below to see the most basic stir fry cooking process. How to prepare protein for stir fry. Most of these dishes require a simple marinade and/or sauce. This easy homemade stir fry sauce is using soy sauce and great with chicken, beef and vegan recipes. To make the sauce, you can either mix all the sauce ingredients together in a bowl, or shake it up in a jar. Watch the video below to see the most basic stir fry cooking process. The heat is what activates the thickener to swell and instantly thicken the liquid in only a minute or two. You can replace the soy sauce with any other sauces. ...
Luka Doncic Overseas Jersey / NBA - Énervé, Luka Doncic déchire son maillot : Recevez une alerte avec les dernières annonces pour « luka doncic jersey » dans canada. . Doncic is listed as questionable for monday's game against sacramento with a left elbow contusion, brad townsend of the dallas morning news reports. Breathable and dry wicking material. Now, the first jersey donned by luka doncic during his nba career is on the auction block and about to sell for a big price. Dallas mavericks forward luka doncic (77) of germany keeps the ball from la clippers guard patrick beverley (21) during the first half of an nba basketball. Bekijk onze luka doncic jersey selectie voor de allerbeste unieke of custom handgemaakte items uit onze herenkleding shops. Free shipping on all orders. When things aren't going this naturally frustrated doncic, but his anger came to a head when he missed two free throws in the second quarter. A look at the calculated cash earnings fo...


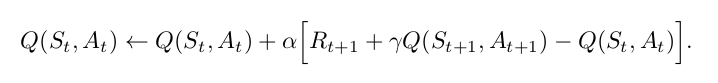



Komentar
Posting Komentar